YS
Hello
I found a method in the help
"getFilePath ( String DefName, String DefExt, String DefDir, String Title, int Options )",
it provides an array of selected files.
Also in the help I found the method
"getData ( )",
which produces an array of bytes (which is what I want).
Using a report, I am trying to output an array of bytes to a text file.
Script code:
function getImportFile() {
var selFile = Dialogs.getFilePath("",
"*.pdf!!Adobe Acrobat Files|*.pdf|Text Files|*.txt||",
"",
"Select file to be opened",
0)[0];
Dialogs.MsgBox("You selected: " + selFile.getName());
//the file's data is available via selFiles[i].getData() which returns the content as a byte[].
if (selFile != null) {
return selFile;
}
return null;
}
function main() {
var importFile = getImportFile();
if (importFile != null) {
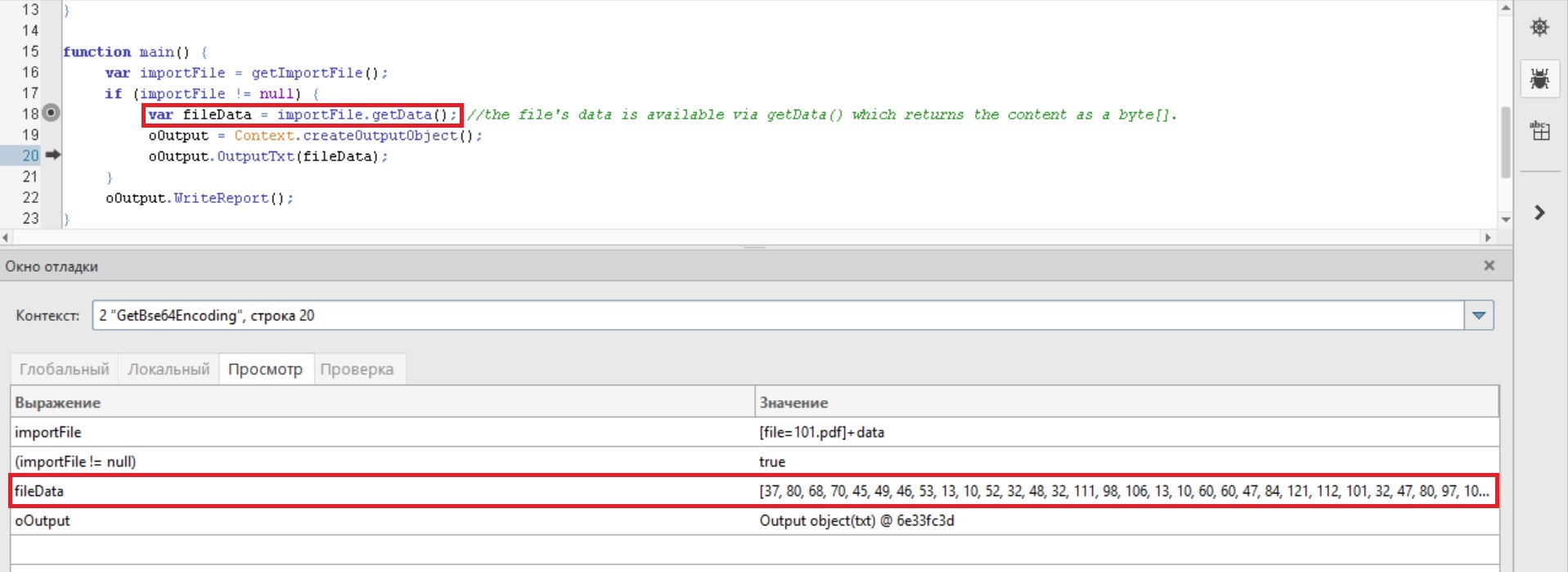
var fileData = importFile.getData(); //the file's data is available via getData() which returns the content as a byte[].
oOutput = Context.createOutputObject();
oOutput.OutputTxt(fileData);
}
oOutput.WriteReport();
}
main();When debugging this script, I check the contents of the "fileData" variable, the data is correct (see pic. "ScreenShotOfValues.jpg").
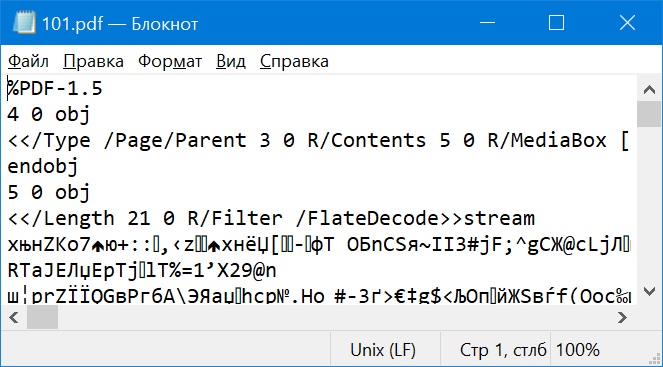
However, when outputting a text file, its content (see pic. "ScreenShotOfOutput.jpg") contains data that does not resemble the contents of a pdf file (see pic "ScreenShotOfPdfContent.jpg").
When using additional function:
function bin2string(array){
var result = "";
for(var i = 0; i < array.length; ++i){
result+= (String.fromCharCode(array[i]));
}
return result;
}The content of the resulting text file is similar to the content of the pdf file that I opened in notepad, but after saving it as a PDF file, Adobe Reader cannot open that PDF file.
Tell me please how I can get the contents of a pdf file as an array of bytes.
Hi,
as far as I know, a pdf file is (at least in parts) binary data. so you should not experiment with converting the file content using String methods like OutputTxt or String.fromCharCode. The most you can do is reading such a file from somwhere and writing it as-is to somewhere else. With the String methods you always run into trouble that they try to interpret the bytes using some encoding like your local Windows codepage or UTF-8 and mapping that to characters. This may fail occasionally, when you have binary data, which is invalid in the encoding, so you lose information this way. With further transformations back to binary this information cannot be recovered. Also it is the question, if the mapping String -> File is done using the same encoding as was used for the interpretation.
Example: String.fromCharCode expects a Unicode code point between U+0 and U+FFFF. But you are giving it a single byte. If your source file were encoded in UTF-8, a single unicode character of a code-point beyond U+7F would show up in your file as 2 or more bytes. This is something your method does not take into consideration. You assume the byte value is the Unicode code-point.
Hello M. Zschuckelt
Thank you very much for your response! I needed to read the pdf file into an array of bytes and then, encode them in Base64, then save them to txt.
The second action I needed to open this txt-file, read the bytes, decode them, and then create a pdf file and write the received (decoded) bytes there.
Text file with encoded bytes created without problems.
Then I found a topic:
https://www.ariscommunity.com/users/jhroza/2015-03-04-create-excel-2010-xlsx-format-file-script
So I used the getCurrentPath() and getSelectedFile() methods (after the WriteReport() method), I took the generated file, load it to Java.
In Java, used FileOutputStream to overwrite a file, writing decoded bytes into it, saved this file.
This decoded pdf file opened successfully.
P.S.
This report is a check for further action - creating an xml file and adding a PDF file to it as a code in Base64 format












{kind=link}
{kind=link}
{kind=link}