

![]()
Last week I shared my thoughts around the reason why organizations should consider engaging in process management and process documentation (or known better as process modeling) in the first place. This week’s episode evolves around the dichotomy of process modeling: it virtually always serves two purposes, but more about that later on this week’s blog.
Let’s first start with painting a picture of the most common practice I encounter when speaking to customers and prospects and you can be the judge of whether or not you recognize this. An organization has decided that business processes should be documented, and this can be the result of an upcoming or already in progress ERP implementation, or the result of an audit gone wrong or simply because some top executive came into the organization with previous experience on this topic. Certainly in the case of the ERP implementation, the process modeling team is positioned within the IT function and more specific within the project team for the ERP project. Please don’t get me wrong, this is fine to start with, but it’s certainly not ok to keep it up like that.
The processes that have been modeled are very system-oriented as they are documented in the perspective of the implementation of an ERP system and thus have a strong emphasis on capturing the processes that are covered by the ERP system. After the project has ended two things can happen (sequentially, in parallel, doesn’t matter):
The documented processes disappear into a digital cabinet never to be looked at again (at least not structurally, although I may happen that in the case of a major incident with the ERP system, the documented process needs to be looked at and perhaps even updated…). The organization really like the modeling of the processes and is expanding it’s reach beyond the ERP system, for example, to capture the HR processes or the internal IT processes (ITSM is always an easy target).
Fast forward a couple of months and somebody in the organization remembers all of those processes that have been modeled a while ago and wonders what could or should be done with them. This often preludes the start of an update project, maybe even triggered by the fact that the organization is planning for the migration into a new version of their ERP system (migrations to SAP 4/HANA are quite in demand right now). Anyway, all of these processes mentioned above have one thing in common, they are created with the purpose of documentation and this brings me to the core point for this blog: process models typically serve two purposes:
- Content creation/maintenance
- Consumption
I think I need to explain that. Process models are created initially with a purpose in mind and the question that needs to be asked is the following:
What are we going to use this model for?
Purpose 1 is the typical purpose that is applied during ERP projects and IT driven process documentation projects and treats the process documentation experts as the most important users of the models. You model to documentation and that’s pretty much it.
Purpose 2 takes the end user (the actors in the processes that have been modeled) as the center piece and ponders the question: How should we visualize this process content to ensure optimal adoption by the end users?
Again, both purposes are important and need to co-exist, the problem I run into a lot with clients is that they do not yet understand that purpose 2 even exists and thus solely focus on the first purpose. Let me illustrate this with an example. Imagine that you run an R&D lab with multiple labs per floor and with multiple workstations per lab. You can imagine that each workstation and each lab as a whole has a whole lot of safety requirements and protocols. Your main objective is to model this AND make sure that the lab users (the R&D professionals) will actually use this info and can find it easily.
The first model that is created typically is a simple function tree model that defines the structure of the lab, and the floors and the workstations. For each lab and workstation you can capture all the relevant data in function allocation diagrams. For purpose 1 this is absolutely perfect, no remarks there. From purpose 2 a function tree is boring, complex and no fun at all (and thus less to almost none adoption by the end users). So, how can you mitigate that?

In some cases this warrants the creation of a second model that is purely focused on purpose 2 and you use the map of the lab to highlight the workstations and link each workstation to the function allocation diagram to ensure that at the moment the scientist click on his/her workstation they immediately see all of the linked protocols, requirements, and other important information right in their screen. The end user will relate much better to the map of his/her lab and this will increase the adoption of the content tremendously. In the end, this is why you document process information in the first place: to have it used by the end users.
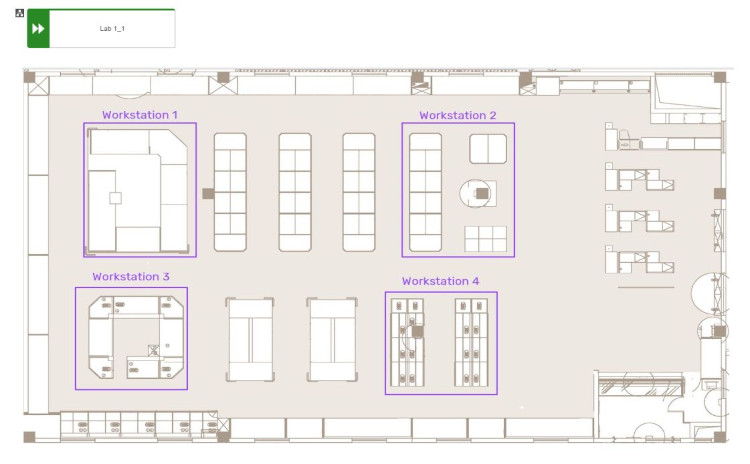
Now, this is something that you won’t do for each and every process, simply because it would increase the workload on the content creation too much, so you need to focus and decide when and how you can apply this approach. For the rest of the process models the BPM experts need to think about how to best balance the need for both purposes and sometimes this will mean a larger focus on purpose 1 and sometimes the focus needs to be on purpose 2. That is a tight rope to walk, but if you ignore purpose 2, I can predict that the content will sit in digital repository gathering digital dust. Such a waste of bits and bytes and all the effort put into it.
This dual purpose idea also has consequences for the governance and ownership for the process content, which I will take on as the topic for next week.
Ciao, Caspar










